MySQL笔记之基础篇
大约 6 分钟
MySQL架构
- server层:连接器、分析器、优化器、执行器
- 存储引擎层,比较有名引擎包括:innodb、myisam、memory
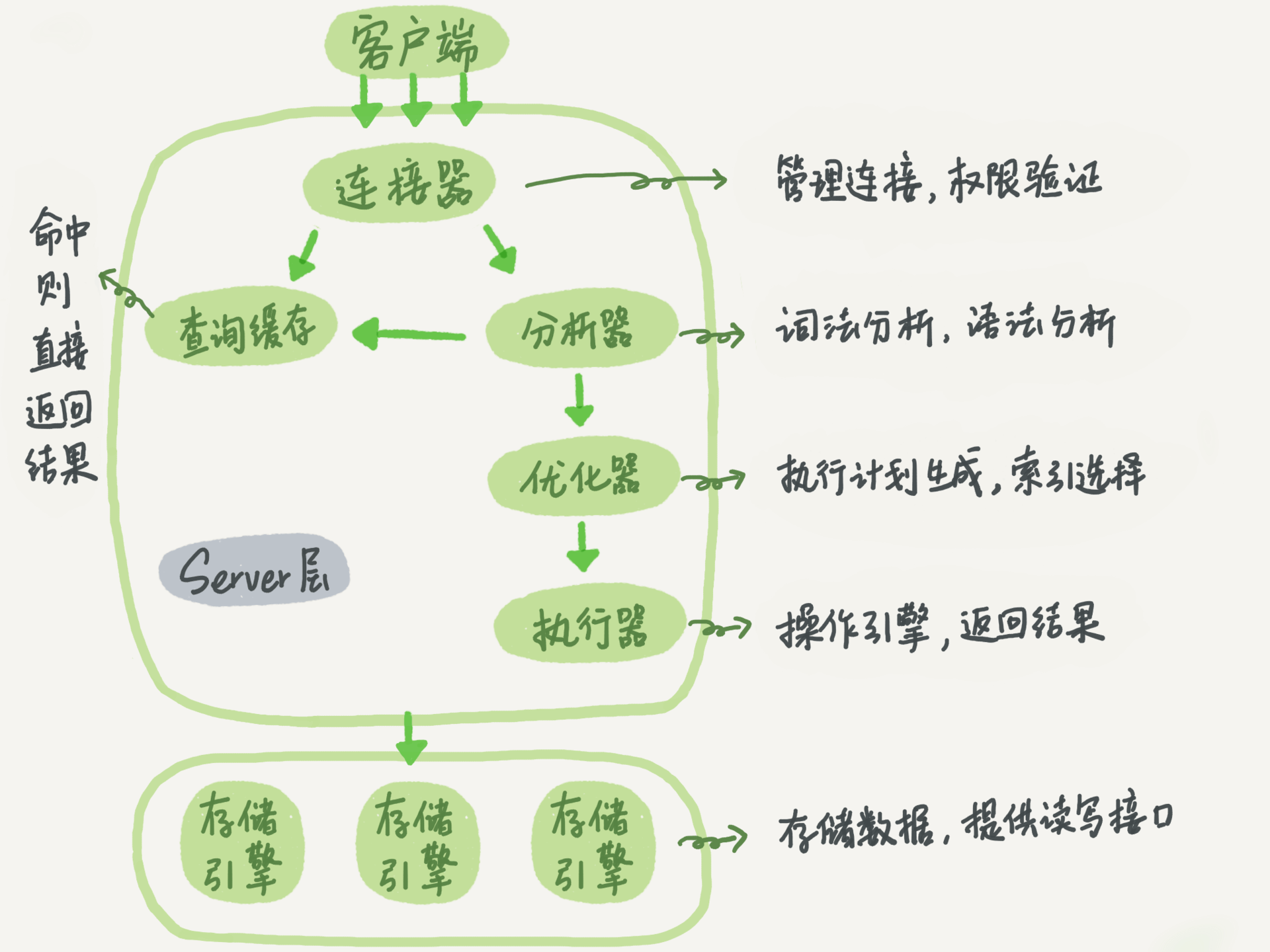
SQL查询语句的执行
- 连接器->查询缓存(8.0版本已废弃)->分析器->优化器->执行器
- rows_examined 的字段,表示这个语句执行过程中扫描了多少行
- 查询缓存在每次表数据更新的时候就会清除缓存
SQL更新语句的执行
- 连接器->分析器->优化器->执行器->存储引擎->执行器->存储引擎
- 执行器操作存储引擎获取要执行的记录
- 拿到记录后执行器对指定字段的结果进行更改
- 执行器调用存储引擎进行数据更改,存储引擎将数据写到内存,并且记录redolog,日志记录的状态为prepare
- 执行器生成操作的binlog日志,
- 执行器调用事务提交接口,引擎将刚刚写入的redolog改成commit状态
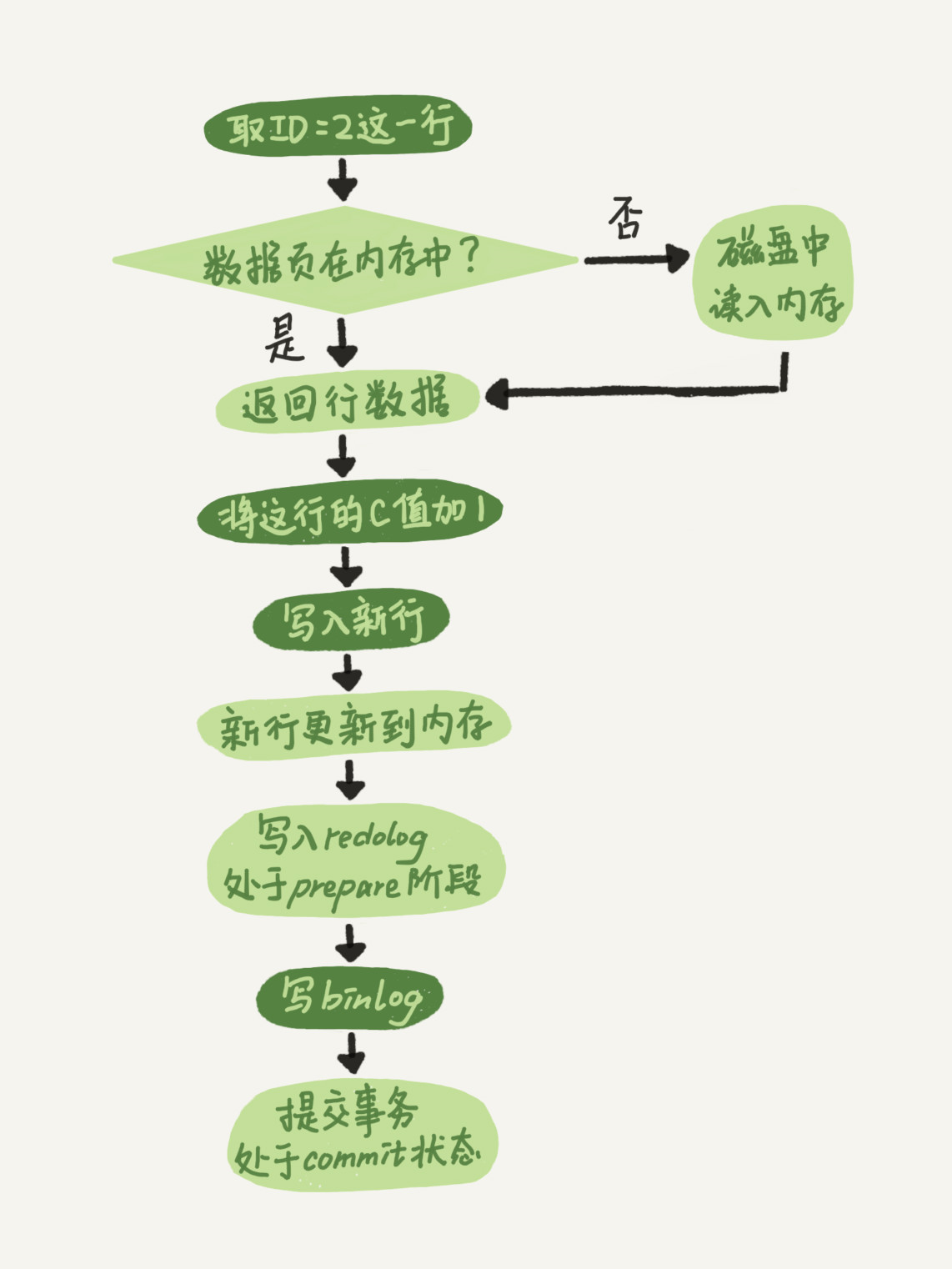
执行器SQL更改流程 - redo log 的写入拆成了两个步骤:prepare 和 commit,这就是"两阶段提交"。
- redolog和binlog的区别
- redolog是引擎层的日志,innodb独有的
- binlog是server层的日志,所有引擎都可以使用
- redo log 是物理日志,记录的是“在某个数据页上做了什么修改”;binlog 是逻辑日志,记录的是这个语句的原始逻辑,比如“给 ID=2 这一行的 c 字段加 1 ”。
- redo log 是循环写的,空间固定会用完;binlog 是可以追加写入的。“追加写”是指 binlog 文件写到一定大小后会切换到下一个,并不会覆盖以前的日志。
- Binlog有两种模式,statement 格式的话是记sql语句, row格式会记录行的内容,记两条,更新前和更新后都有。
事务
- 事务的特性
- 原子性
- 隔离性
- 一致性
- 持久性
- 事务的隔离级别
- 读未提交,在一个事务里可以读取其他事务未提交的数据变更
- 读提交,在一个事务里只能读取已提交事务的变更数据
- 可重复性读,在一个事务里可以多次读取到当前事务第一次读取的数据
- 串行化,一个事务结束,另一个事务才能继续操作
隔离级别越高,并发性越低,安全性越高
幻读:第一次查询不存在,然后insert失败,这个时候出现了幻读,串行化没幻读,其余都有
- 事务隔离的实现
- 每条记录在更新的时候都会记录一条回滚操作,回滚日志(undolog)在没有比这个版本更老的视图的时候进行删除
- 同一个记录在系统中存在多个版本,也就是多版本并发控制(MVCC)
- 尽量避免使用长事务,长事务会占用较大的磁盘空间,长事务占用大量的锁资源,会拖垮整个库。长事务是指执行时间长的SQL变更
- 避免长事务,设置SQL语句操作超时时间、开启自动提交、避免只读事务
- 事务默认都是开启的,可以通过
set autocommit=0配置进行关闭 - 可以通过显示的命令开启事务
索引
索引的出现其实就是为了提高数据查询的效率,就像书的目录一样
- 常见的索引数据结构
- 哈希,适用于精确查询,范围查询效率贼低
- 哈希冲突时使用链表把相同hash的值搞在一块
- 有序数组,在等值查询和范围查询场景中的性能就都非常优,但是在更新数据时效率太低
- 树,每一个索引在 InnoDB 里面对应一棵 B+ 树。
- 二叉搜索树:每个节点的左儿子小于父节点,父节点又小于右儿子
- InnoDB的索引
- 主键索引
- 非主键索引
- 在使用非主键索引查询时,首先要先找到主键索引,然后根据主键索引查到行记录,这个过程称为回表
- 主键索引的B+树的叶子节点存储的是page (页),一个页里面可以存多个行
- 非主键索引的叶子节点存储的是主键
- 基于非主键索引的查询需要多扫描一棵索引树。因此,我们在应用中应该尽量使用主键查询。
- 覆盖索引,比如使用普通索引去查询主键字段或普通索引上的字段,则会命中覆盖索引,无需回表,减少了一次扫描索引树。
- 覆盖索引可以减少树的搜索次数,显著提升查询性能,所以使用覆盖索引是一个常用的性能优化手段。
- 索引遵循最左前缀原则,最左前缀可以是联合索引的最左 N 个字段,也可以是字符串索引的最左 M 个字符
- 自增主键可以避免页分裂,从性能和存储空间方面考量,自增主键往往是更合理的选择
- 主键长度越小,普通索引的叶子节点就越小,普通索引占用的空间也就越小。
- 联合索引创建
- 第一原则是,如果通过调整顺序,可以少维护一个索引,那么这个顺序往往就是需要优先考虑采用的。
- 比如字段 a,b在使用时,都会被频繁查询,a的评率更高,一般建议搞一个 (a,b) 和一个(b)
- 索引下推
- 在使用联合索引时,当命中了最左原则,在MySQL5.6版本以上会根据后续条件的值判断索引值是否符合,减少回表次数
- 索引重建过程
- 主键索引重建,使用
alter table T engine=InnoDB语句 - drop主键索引会导致其他索引失效,但drop普通索引不会。
- 索引总结
- 覆盖索引:如果查询条件使用的是普通索引(或是联合索引的最左原则字段),查询结果是联合索引的字段或是主键,不用回表操作,直接返回结果,减少IO磁盘读写读取正行数据
- 最左前缀:联合索引的最左 N 个字段,也可以是字符串索引的最左 M 个字符
- 联合索引:根据创建联合索引的顺序,以最左原则进行where检索,比如(age,name)以age=1 或 age= 1 and name=‘张三’可以使用索引,单以name=‘张三’ 不会使用索引,考虑到存储空间的问题,还请根据业务需求,将查找频繁的数据进行靠左创建索引。
- 索引下推:like 'hello%’and age >10 检索,MySQL5.6版本之前,会对匹配的数据进行回表查询。5.6版本后,会先过滤掉age<10的数据,再进行回表查询,减少回表率,提升检索速度